To evaluate counterfactual fairness we will be using the “law school” dataset (McIntyre and Simkovic 2018).
The Law School Admission Council conducted a survey across 163 law schools in the United States. It contains information on 21,790 law students such as their entrance exam scores (LSAT), their grade-point average (GPA) collected prior to law school, and their first year average grade (FYA). Given this data, a school may wish to predict if an applicant will have a high FYA. The school would also like to make sure these predictions are not biased by an individual’s race and sex. However, the LSAT, GPA, and FYA scores, may be biased due to social factors.
We start by importing the data into a PandasDataFrame.
import pandas as pddf = pd.read_csv("_data/law_data.csv", index_col=0)df.head()
race
sex
LSAT
UGPA
region_first
ZFYA
sander_index
first_pf
0
White
1
39.0
3.1
GL
-0.98
0.782738
1.0
1
White
1
36.0
3.0
GL
0.09
0.735714
1.0
2
White
2
30.0
3.1
MS
-0.35
0.670238
1.0
5
Hispanic
2
39.0
2.2
NE
0.58
0.697024
1.0
6
White
1
37.0
3.4
GL
-1.26
0.786310
1.0
Pre-processing
We now pre-process the data. We start by creating categorical “dummy” variables according to the race variable.
Counterfactual fairness enforces that a distribution over possible predictions for an individual should remain unchanged in a world where an individual’s protected attributes A had been different in a causal sense. Let’s start by defining the /protected attributes/. Obvious candidates are the different categorical variables for ethnicity (Asian, White, Black, etc) and gender (male, female).
A = ["Amerindian","Asian","Black","Hispanic","Mexican","Other","Puertorican","White","male","female",]
Training and testing subsets
We will now divide the dataset into training and testing subsets. We will use the same ratio as in (Kusner et al. 2017), that is 20%.
from sklearn.model_selection import train_test_splitdf_train, df_test = train_test_split(df, random_state=23, test_size=0.2);
Models
Unfair model
As detailed in (Kusner et al. 2017), the concept of counterfactual fairness holds under three levels of assumptions of increasing strength.
The first of such levels is Level 1, where \hat{Y} is built using only the observable non-descendants of A. This only requires partial causal ordering and no further causal assumptions, but in many problems there will be few, if any, observables which are not descendants of protected demographic factors.
For this dataset, since LSAT, GPA, and FYA are all biased by ethnicity and gender, we cannot use any observed features to construct a Level 1 counterfactually fair predictor as described in Level 1.
Instead (and in order to compare the performance with Level 2 and 3 models) we will build two unfair baselines.
A Full model, which will be trained with the totality of the variables
An Unaware model (FTU), which will be trained will all the variables, except the protected attributes A.
Let’s proceed with calculating the Full model.
Full model
As mentioned previously, the full model will be a simple linear regression in order to predict ZFYA using all of the variables.
from sklearn.linear_model import LinearRegressionlinreg_unfair = LinearRegression()
The inputs will then be the totality of the variabes (protected variables A, as well as UGPA and LSAT).
from sklearn.metrics import mean_squared_errorRMSE_unfair = np.sqrt(mean_squared_error(df_test["ZFYA"], predictions_unfair))float(RMSE_unfair)
0.8666783694285809
Fairness through unawareness (FTU)
As also mentioned in (Kusner et al. 2017), the second baseline we will use is an Unaware model (FTU), which will be trained will all the variables, except the protected attributes A.
linreg_ftu = LinearRegression()
We will create the inputs as previously, but without using the protected attributes, A.
Still according to (Kusner et al. 2017), a Level 2 approach will model latent ‘fair’ variables which are parents of observed variables.
If we consider a predictor parameterised by \theta, such as:
\hat{Y} \equiv g_\theta (U, X_{\nsucc A})
with X_{\nsucc A} \subseteq X are non-descendants of A. Assuming a loss function l(.,.) and training data \mathcal{D}\equiv\{(A^{(i), X^{(i)}, Y^{(i)}})\}, for i=1,2\dots,n, the empirical loss is defined as
which has to be minimised in order to \theta. Each n expectation is with respect to random variable U^{(i)} such that
U^{(i)}\sim P_{\mathcal{M}}(U|x^{(i)}, a^{(i)})
where P_{\mathcal{M}}(U|x,a) is the conditional distribution of the background variables as given by a causal model M that is available by assumption.
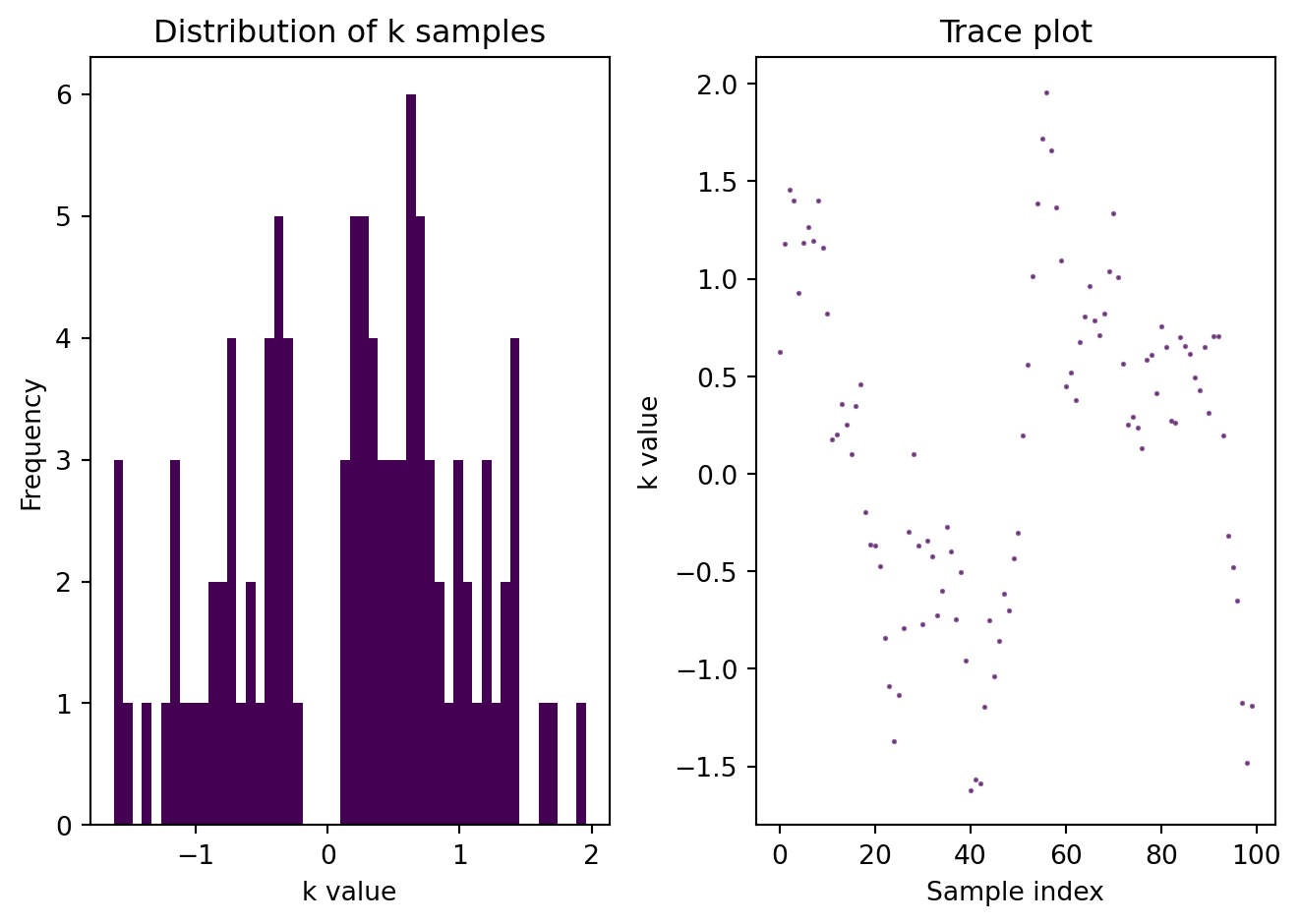
If this expectation cannot be calculated analytically, Markov chain Monte Carlo (MCMC) can be used to approximate it as in the following algorithm.
We will follow the model specified in the original paper, where the latent variable considered is K, which represents a student’s knowledge. K will affect GPA, LSAT and the outcome, FYA. The model can be defined by:
Finally, in Level 3, we model GPA, LSAT, and FYA as continuous variables with additive error terms independent of race and sex (though these error terms may in turn be correlated with one-another).
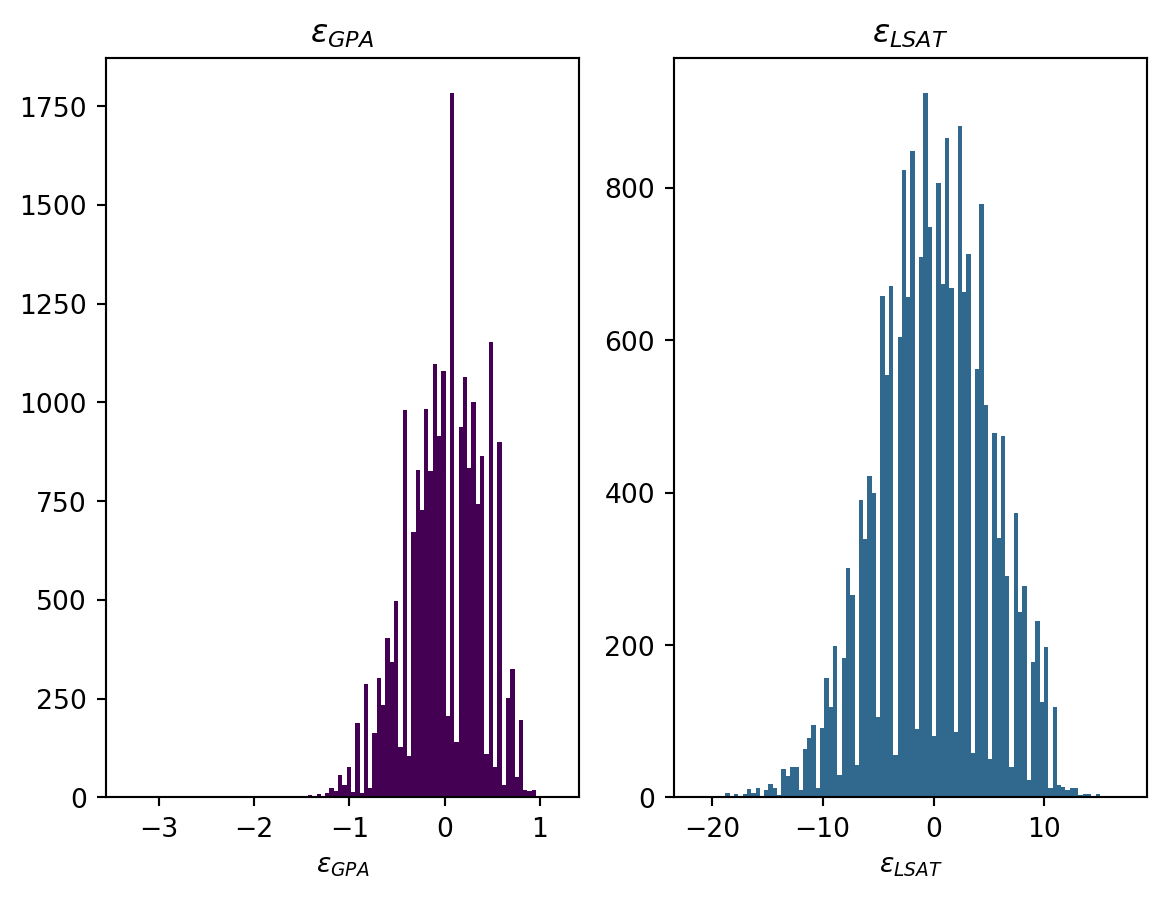
We estimate the error terms \epsilon_{GPA}, \epsilon_{LSAT} by first fitting two models that each use race and sex to individually predict GPA and LSAT. We then compute the residuals of each model (e.g., \epsilon_{GPA} =GPA−\hat{Y}_{GPA}(R, S)). We use these residual estimates of \epsilon_{GPA}, \epsilon_{LSAT} to predict FYA. In (Kusner et al. 2017) this is called Fair Add.
Since the process is similar for the individual predictions for GPA and LSAT, we will write a method to avoid repetion.
Let’s visualise the \epsilon distribution quickly:
We finally use the calculated \epsilon to train a model in order to predict FYA. We start by getting the subset of the \epsilon which match the training indices.
X = np.hstack( ( np.array(epsilons_gpa[df_train.index]).reshape(-1, 1), np.array(epsilons_LSAT[df_train.index]).reshape(-1, 1), ))X
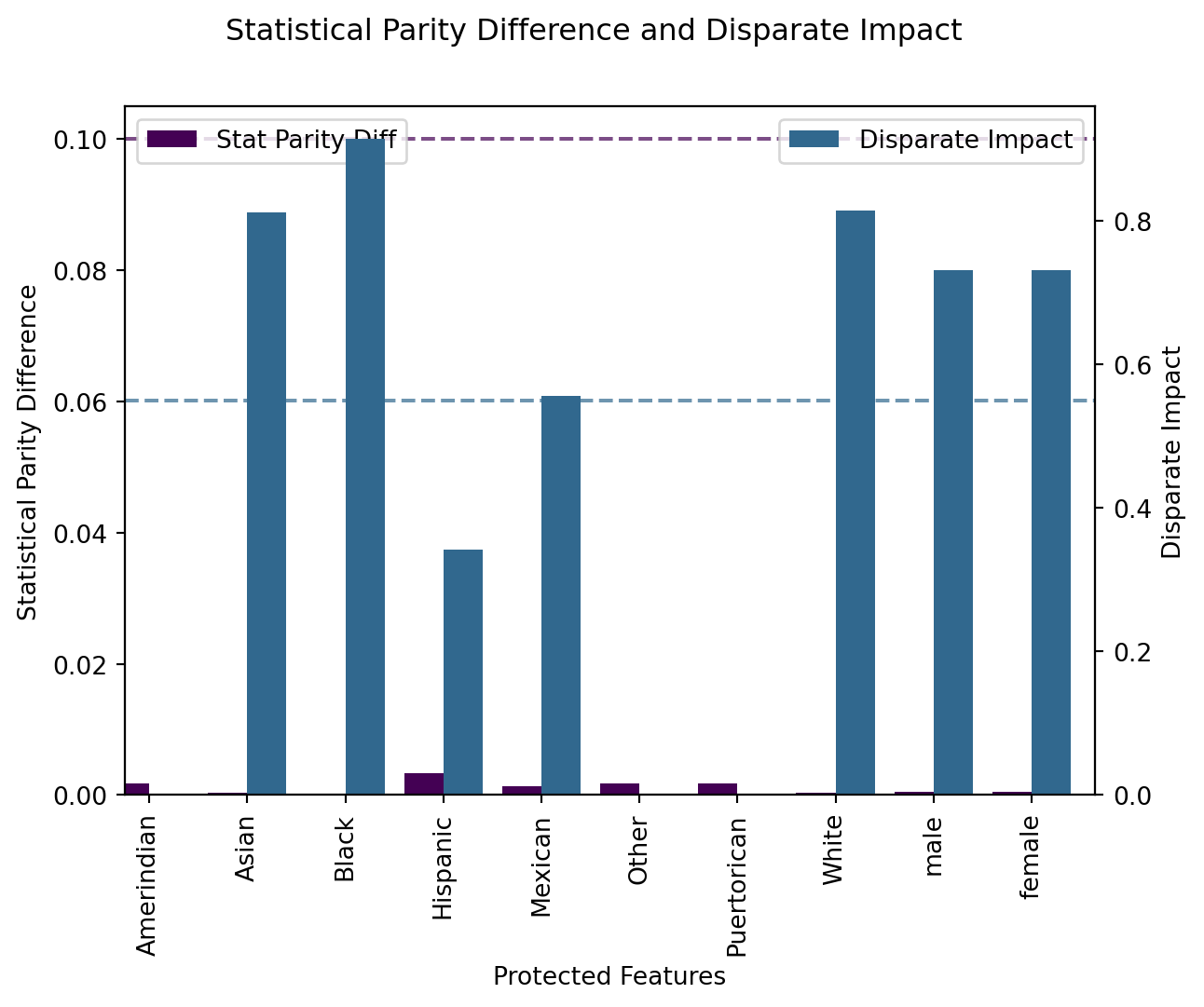
Typically a SPD > 0.1 and a DI < 0.9 might indicate discrimination on those features. In our dataset, we have two features (Hispanic and Mexican) which clearly fail the DI test (with DI < 0.9), indicating potential discrimination. The SPD values for these features are relatively small, suggesting that while there may be disparate impact, the absolute difference in proportions is not as pronounced.
for a in ["Mexican", "Hispanic"]: spd = demographic_parity_difference(y_true=df_train["ZFYA"], y_pred=df_train["ZFYA"], sensitive_features = df_train[a])print(f"SPD({a}) = {spd}") di = demographic_parity_ratio(y_true=df_train["ZFYA"], y_pred=df_train["ZFYA"], sensitive_features = df_train[a])print(f"DI({a}) = {di}")
Kusner, Matt J., Joshua Loftus, Chris Russell, and Ricardo Silva. 2017. “Counterfactual Fairness.” In Advances in Neural Information Processing Systems, 4066–76.
McIntyre, Frank, and Michael Simkovic. 2018. “Are Law Degrees as Valuable to Minorities?”International Review of Law and Economics 53: 23–37.